Технология RAIDIX QoSmic. Машинное обучение для балансировки производительности
Как я обещал в предыдущей заметке, в этот раз мы расскажем о том, как работает машинное обучение в функции QoSmic, с помощью которой можно выставлять приоритеты по приложениям. Для того чтобы получить информацию из первых рук, я задал несколько вопросов руководителю исследовательской лаборатории Рэйдикс Светлане Лазаревой.
СП: Светлана, каков принцип работы QoSmic?
СЛ: Все запросы, поступающие к СХД, проходят через модуль распознавания приложений (см. рис. 1). Модуль работает в двух режимах:
- Обучения: мы «знакомим» нашу систему хранения с новым приложением, которое планируется распознавать в целях работы QoS или упреждающего чтения
- Распознавания: приложения для модуля QoS или упреждающего чтения идентифицируются в режиме реального времени.
Запросы в течении t секунд (например, 20 сек.) собираются в модули распознавания, далее данный лог анализируются, и по нему строятся I/O сигнатуры. В режиме обучения сигнатуры помечаются именем приложения, в режиме распознавания подаются в модуль для идентификации. В качестве алгоритма классификации («Модель» на рис. 1) используется Random Forest. У данного алгоритма есть преимущества по сравнению с другими алгоритмами классификации Data Mining:
- высокая скорость обучения
- неитеративное обучение (алгоритм завершается за фиксированное число операций)
- масштабируемость (способность обрабатывать большие объемы данных)
- высокое качество получаемых моделей (сравнимое с нейронными сетями и ансамблями нейронных сетей)
- малое количество настраиваемых параметров
При этом у него есть и недостатки. Один из них – это склонность к переобучению на зашумленных данных. Впрочем, это проблема решается с помощью применения фильтров типа FCBF.
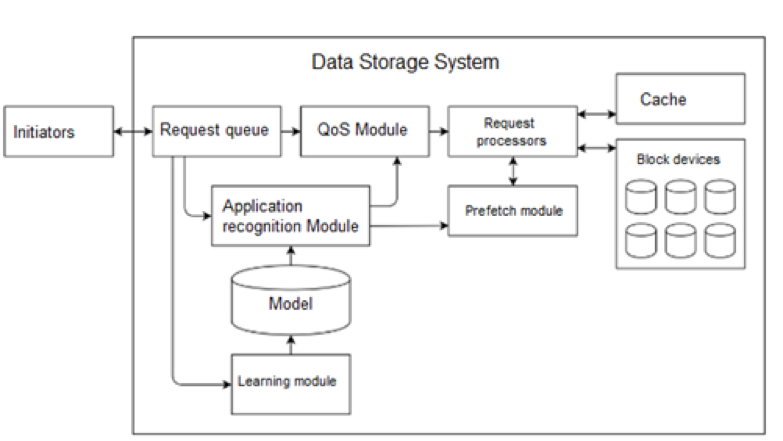
Рисунок 1 — Схема распознавания приложений
СП: Какие основные параметры используются для распознавания приложений?
СЛ: Для идентификации приложения нам достаточно знать четыре характеристики: длину запроса, тип запроса (чтение или запись), оффсет (адресное пространство), время прихода запроса. На основании этих четырех параметров мы строим I/O сигнатуры.
СП: Как шла разработка, какие идеи проверяли?
СЛ: Сначала мы пытались искать известные «паттерны» (последовательности подряд идущих длин) для данного приложения. Данный подход отлично себя показал на примере бенчмарков, ПО для резервного копирования и антивирусов. Также мы тестировали различные алгоритмы машинного обучения. Сначала научились идентифицировать приложения с низкой вероятностью, но с добавлением специальных атрибутов в I/O сигнатуру довели точность идентификации до 99,99%.
СП: Какие параметры оказались совершенно не существенными для определения приложений, а что преподнесло сюрприз?
СЛ: Ключевым для идентификации оказалось распределение длин запросов от конкретного приложения. Несущественным параметром оказалось само адресное пространство, т. е. мы не идентифицируем приложение по его адресам и местоположению.
СП: Что произойдет, если с СХД начнет работать неизвестное приложение?
СЛ: Алгоритм выдаст ответ “не удалось определить”. Random Forest – вероятностный алгоритм. Когда начинает работать неизвестное приложение, он оценивает вероятность совпадения данного приложения с ранее обнаруженными в системе. В нашем случае приложение распознается, если вероятность превышает 60%.
СП: Как администратору понять, что пора выполнить переобучение?
СЛ: Переобучение стоит выполнить, если часто выдается вопрос “не удалось определить” или неправильно определяются приложения. В процессе обучения сам алгоритм может подсказать, что полученных сигнатур недостаточно для точной идентификации.
СП: Как ты думаешь, должен ли администратор ИТ-инфраструктуры будущего быть немного Data Scientist?
СЛ: Это может прозвучать слишком радикально, но я думаю, что в будущем не будет администраторов как таковых. Дальнейшее развитие алгоритмов машинного обучения и искусственного интеллекта сведет вовлеченность человека в управление инфраструктурой к минимуму.
Светлана, спасибо за ответы! Так осуществляются распознавание в модуле QoSmic с помощью алгоритмов машинного обучения.
Следите за нашими обновлениями, чтобы узнать больше о предиктивной аналитике, автоматизации системных настроек и других областях применения искусственного интеллекта!